Des Transformers plus rapides et moins couteux avec Pytorch 2.0
Par Vincent Coulombe, 22 juin 2023
Pytorch 2.0 est maintenant arrivé! Et il nous a amené tout plein de cadeaux. Notamment la nouvelle méthode torch.compile() qui permet de compiler le graph de calcul de rétropropagation directement sur GPU (à la TensorFlow). Le tout permet d’entraîner les modèles (ou tout autre nn.Module) environ 2.25 fois plus vite!
Mais ce n’est pas tout! Pytorch 2.0 arrive aussi avec son implémentation du « flash attention », introduit dans l’article de Dao. Soit une implémentation du mécanisme d’attention avec un noyau optimisé, autant pour la performance que pour la gestion de la mémoire sur GPU tel que présenté dans l’article de Wu
Introduit dans l’article Attention is all you need, et présent dans toutes les architectures neuronales modernes, le mécanisme d’attention permet aux modèles de discriminer ou de privilégier certaines informations afin de prendre une décision optimale. Bref, il porte plus ou moins attention aux différents tenseurs en entrée. Le tout est expliqué en détail dans mon dernier article de blogue sur le NLP. Où il est expliqué que le cœur de ce mécanisme n’est qu’un produit matriciel de tenseurs. Produit matriciel qui, avant Pytorch 2.0, était souvent effectué en Python. Par exemple, dans le modèle NanoGPT d’Andrej Karpathy (dont voici le code et le tutoriel), mais maintenant, il peut être totalement résumé via l’API scaled_dot_product_attention de Pytorch.
En lui passant simplement les paramètres suivants :
Le tenseur de requête
Soit les plongements de la couche précédente (autoattention).
Le tenseur de clé
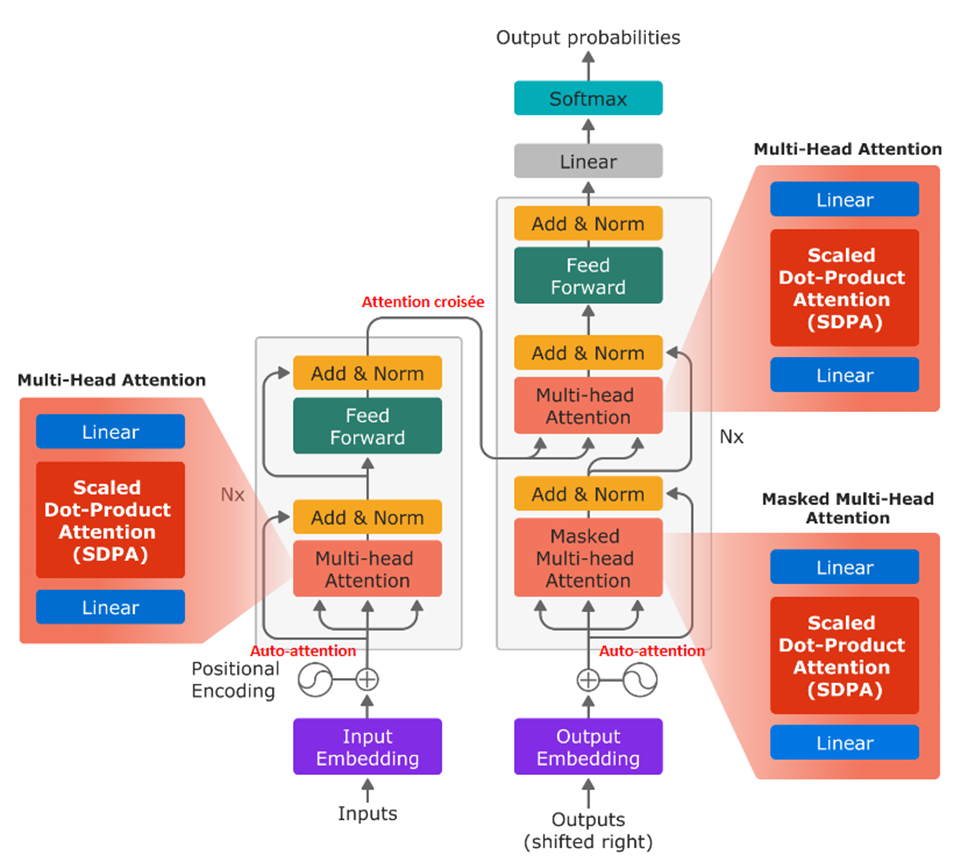
Soit les plongements de la couche précédente (autoattention) ou bien des plongements « externes » à l’architecture (attention croisée) Figure 1.
Le tenseur de valeur
Soit les plongements de la couche précédente (autoattention) ou bien des plongements « externes » à l’architecture (attention croisée) Figure 1.
Figure 1 : L’attention croisée, comme présentée ici, n’est que la correspondance entre des plongements « externes » au modèle (ici, le modèle est le décodeur à gauche). Cette correspondance est exprimée via les tenseurs de requête et de clé (voir notre article de blogue). Le tout permet au modèle d’apprendre à tenir compte de différentes sources d’information différentes. Image tirée de Accelerating Large Language Models with Accelerated Transformers.
Le masque d’attention
Un tenseur N x L x S où L x S sont des valeurs binaires (0 ou 1) permettant à la clé de porter (1) ou non (0) attention à la requête.
À noter que la seule différence entre les architectures de type encodeur et celles de type décodeur est au niveau du masque d’attention. Dans l’architecture encodeur, toutes les clés peuvent interroger toutes les requêtes alors que dans l’architecture décodeur, les clés peuvent seulement interroger les requêtes présentes ou passées (Voir Figure 2).
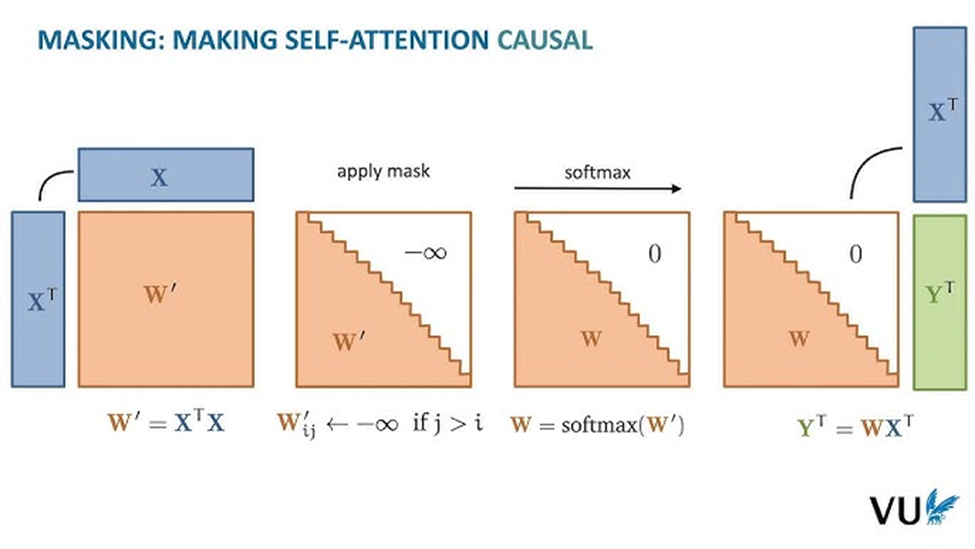
Figure 2 : Attention dite causale c’est-à-dire celle présente dans les architectures de type décodeur soit celles souvent utilisées pour générer du texte ou bien faire de l’analyse temporelle. À noter qu’en pratique la normalisation du calcul d’attention est effectuée via un calcul de softmax. Le petit truc est donc d’initialiser le masque à -∞ pour les relations interplongement qu’on tient à éliminer lors du calcul d’attention (ici, les relations futures). Image à 4 :30 dans cette vidéo.
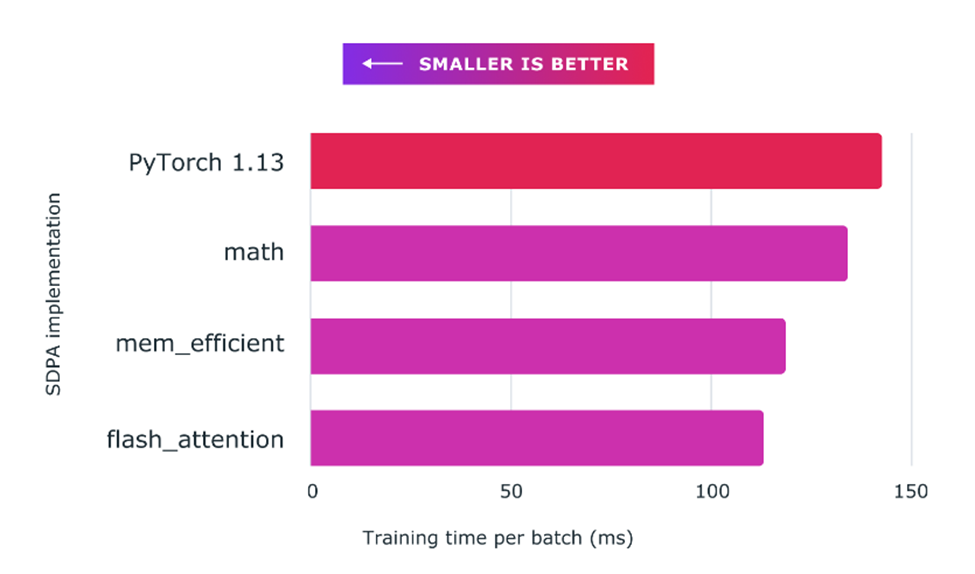
Bref, l’API scaled_dot_product_attention de Pytorch permet de calculer toutes ces variations du mécanisme d’attention (dépendamment des paramètres passés à la fonction) approximativement 25 % plus rapidement que l’implémentation en pure Pytorch (Figure 3), tel que présenté dans le tutoriel de M. Karpathy. Ce qui, à l’échelle des gros transformers, correspond à un gain significatif en termes de vitesse d’inférence et (surtout) de temps d’entraînement!
Figure 3 : Implémentation du mécanisme d’attention en Pytorch. La première ligne initialise le masque (la matrice W de la Figure 2), soit une matrice contenant 1 si on désire une relation d’attention et 0 sinon (à noter l’utilisation de torch.tril pour forcer la causalité). Les éléments nuls du masque sont ensuite initialisés à -∞ (afin qu’ils puissent reprendre la valeur de 0 après le calcul softmax). Finalement, le calcul d’attention entre le tenseur de clé et celui de requête a lieu. Tel que présenté dans notre article de blogue nommé précédemment, ce calcul est normalisé via un calcul de softmax. À noter qu’on effectue également une division par la racine carrée du nombre de requêtes (la taille de la fenêtre de contexte) pour éviter que la softmax ne converge vers un vecteur one-hot. Source de l’image
Figure 4 : Temps d’exécution du code présenté à la Figure 3 (PyTorch 1.13) versus l’API scale_dot_product_attention (flash_attention). Image tirée de Accelerated PyTorch 2 Transformers
Donc, si je récapitule, Pytorch 2.0 fournit deux nouveaux outils intéressants pour nos coffres. Soit, pouvoir compiler le graphe de calcul d’un nn.Module, ce qui permet un gain de plus de 100 % sur la vitesse d’entraînement, ainsi qu’un nouvel API permettant de facilement utiliser le flash attention pour un solide 25 % de gain supplémentaire sur la vitesse d’entraînement.
Nous avons à cœur de protéger vos données. Nous utilisons des cookies pour vous offrir une meilleure expérience numérique. En acceptant, vous consentez à notre utilisation de ces cookies.
Fonctionnel
Toujours activé
Le stockage ou l’accès technique est strictement nécessaire dans la finalité d’intérêt légitime de permettre l’utilisation d’un service spécifique explicitement demandé par l’abonné ou l’utilisateur, ou dans le seul but d’effectuer la transmission d’une communication sur un réseau de communications électroniques.
Préférences
Le stockage ou l’accès technique est nécessaire dans la finalité d’intérêt légitime de stocker des préférences qui ne sont pas demandées par l’abonné ou l’utilisateur.
Statistiques
Le stockage ou l’accès technique qui est utilisé exclusivement à des fins statistiques.Le stockage ou l’accès technique qui est utilisé exclusivement dans des finalités statistiques anonymes. En l’absence d’une assignation à comparaître, d’une conformité volontaire de la part de votre fournisseur d’accès à internet ou d’enregistrements supplémentaires provenant d’une tierce partie, les informations stockées ou extraites à cette seule fin ne peuvent généralement pas être utilisées pour vous identifier.
Marketing
Le stockage ou l’accès technique est nécessaire pour créer des profils d’utilisateurs afin d’envoyer des publicités, ou pour suivre l’utilisateur sur un site web ou sur plusieurs sites web ayant des finalités marketing similaires.