Décrypter le NLP (3e partie) : ChatGPT et l’architecture révolutionnaire des transformers, pour améliorer les performances du traitement du langage naturel
Par Vincent Coulombe, 29 mars 2023
Les mécanismes d’attention ont révolutionné le domaine du traitement du langage naturel (NLP) ces dernières années, entraînant des améliorations significatives dans des tâches telles que la traduction automatique, la compréhension du langage et la génération de texte. Au cœur de cette innovation se trouve l’architecture transformer, qui est devenue le modèle de pointe pour de nombreuses tâches NLP.
L’architecture du transformer est basée sur le concept d’attention, qui permet au modèle de se concentrer sélectivement sur différentes parties de la séquence d’entrée lors du calcul de la sortie. Ceci est particulièrement utile pour les tâches NLP, où la séquence d’entrée peut être très longue et complexe, et les architectures récurrentes ou convolutives traditionnelles peuvent avoir du mal à capturer les informations contextuelles nécessaires.
Dans cet article, nous explorerons le mécanisme d’attention et son rôle dans l’architecture du transformer. Nous discuterons des composantes clés du transformateur, y compris l’attention multitête et l’encodage positionnel, et comment ils fonctionnent ensemble pour obtenir des performances de pointe sur un large éventail de tâches NLP.
Ce n’est pas mêlant. Cette architecture, provenant de l’article Attention is all you need, est tellement performante qu’elle a été utilisée pour créer l’introduction que vous venez de lire! Le tout, via ChatGPT soit, probablement le transformer le plus connu présentement.
Vous aurez donc deviné que l’architecture transformer est au menu ce mois-ci! Je vous propose donc une gentille introduction aux concepts, suivie d’une introduction pas mal moins gentille (pour les plus curieux) et finalement un exemple d’implantation en Python via le populaire framework Pytorch.
Introduction au mécanisme d’attention
En gros, les transformers reposent sur un algorithme nommé le mécanisme d’attention. Celui-ci a été introduit en 2017 et demeure (en date d’écrire ces lignes) la dernière grande innovation architecturale en deep learning (ça fait 5 ans, on est dus, guys…).
Donc, si vous comprenez le mécanisme d’attention, vous comprenez également les transformers. Cela dit, ma mission étant de vous faire comprendre les transformers, je vais donc vous entretenir ici en long et en large du mécanisme d’attention.
Pourquoi le mécanisme d’attention est aussi révolutionnaire?
La première chose à saisir pour bien comprendre le fonctionnement du mécanisme d’attention est le contexte dans lequel sa création fût effectuée.
On se souvient, (sinon allez voir mon article précédent sur les réseaux de neurones récurrents), qu’en 2017 l’état de l’art en NLP était les LSTM et un paquet de add-on (comme le CRF) qui venaient corriger certaines de ses lacunes. Toutefois, ce modèle comportait certaines faiblesses trop importantes pour être ignorées, soit :
Les mots étaient traités 1 par 1. Ce qui rendait le modèle extrêmement lent. Ça limitait la grosseur des réseaux et rendait l’inférence et l’entraînement très couteux (il fallait des ordinateurs puissants)
Les mots étaient traités de gauche à droite et de droite à gauche. Ce qui rendait difficile (même pour les LSTM) de garder fidèlement en mémoire l’information sémantique d’une longue phrase. Les derniers mots prenant plus de place dans celle-ci que les mots plus éloignés. Il en résultait une perte de contexte qui pouvait être catastrophique dans certains cas.
Bref, il nous fallait un héros, un champion, quelqu’un qui serait en mesure de traiter conjointement (en parallèle) tous les mots d’un texte. Palliant ainsi (une pierre deux coups) les deux grosses faiblesses des bi-LSTM.
Le fonctionnement du mécanisme d’attention, gentiment
Étant donné que vous lisez actuellement l’introduction gentille (choix judicieux), je vous propose d’introduire le mécanisme d’attention via un exemple.
Supposons que j’aimerais déterminer laquelle des deux phrases suivantes porte sur la piraterie :
« Le capitaine va parler à l’arbitre au sujet de la punition que celui-ci vient d’annoncer contre son équipe. »
« Le capitaine annonce à son équipage qu’il sera puni pour avoir trop parlé de l’île. »
Rapidement, je me rends compte que si j’utilise des embeddings de mots à la word2vec (pour en savoir plus, vous pouvez vous référer au 1er article de cette série), alors les mots comme « capitaine », « équipage/équipe », « punition/puni » seront traités comme étant quasi identiques. Toutefois, en lisant les phrases, on se rend bien compte que la première parle d’un sportif en désaccord avec la décision d’un officiel alors que la deuxième parle d’un pirate cruel qui punit excessivement son équipage.
Il faut donc trouver une manière de tenir compte du contexte entourant chacun des mots. D’être en mesure de porter une ATTENTION particulière au contexte dans lequel les mots sont utilisés. Le tout, via un MÉCANISME quelconque.
Mieux encore, il faudrait pouvoir entraîner un algorithme à porter une ATTENTION particulière aux groupes sémantiques portant sur la piraterie. Un tel algorithme pourrait donc mettre des poids à chaque mot d’une phrase dépendamment du contexte entourant ceux-ci. Comme :
« Le capitaine va parler à l’arbitre au sujet de la punition que celui-ci vient d’annoncer contre son équipe. »
« Le capitaine annonce à son équipage qu’il sera puni pour avoir trop parlé de l’île. »
Ce qui permettra à l’algorithme d’apprendre qu’un capitaine qui parle à un arbitre n’est probablement pas un pirate, alors qu’un capitaine qui punit son équipage l’est probablement. Ce procédé est très intuitif, puisqu’il ressemble beaucoup à celui que nous, les humains, utilisons pour effectuer ce genre d’analyse. Par exemple, si je vous demandais de trouver les phrases qui portent sur la piraterie, vous porteriez probablement plus attention aux contextes entourant des mots comme « capitaine », « équipage » et « île ». D’ailleurs, ce fonctionnement intuitif est un bonus du mécanisme d’attention. Puisque celui-ci raisonne à peu près comme nous, ses résultats sont facilement interprétables. On a qu’à regarder les scores d’attention que l’algorithme donne à chacun des mots d’une phrase pour comprendre sur quoi l’algorithme s’est basé pour prendre sa décision.
Bref, le mécanisme d’attention est extrêmement puissant parce qu’il est capable :
de traiter tous les mots d’un texte en même temps (en parallèle)
d’apprendre à mettre en contexte les mots d’une phrase afin de prendre une/des décision(s) à partir d’un environnement nuancé et extrêmement riche en information.
d’être très facile à interpréter, donc à comprendre et à améliorer.
Le fonctionnement du mécanisme d’attention, moins gentiment
En premier lieu, retournons en arrière. Plus précisément au moment où j’ai introduit le concept de word embedding. Soit, une structure de donnée (un vecteur) contenant l’ensemble des valeurs sémantiques d’un mot. Eh bien surprise, il s’adonne que j’ai introduit ce concept avec de la suite dans les idées, car les transformers (en NLP) reçoivent en entrée des words embeddings, mais pas les mêmes que ceux obtenus via des algorithmes de type encodeur-décodeur comme Word2vec. À la place, les transformers travaillent avec des embeddings de tokens :
« Les tokens utilisés par les transformers sont des mots (« de », « le », « ils »), des bouts de mots (« vin » ,« cent ») et des lettres (« z », « g », « x ») obtenus via l’algorithme WordPiece. »
Vincent Coulombe, 2023
Par exemple, tokeniser la phrase :
Voici un exemple de mots à tokenizer.
Peut donner les tokens suivants :
Voici un exemple de mots à to ken izer .
L’avantage de séparer les mots ainsi, c’est qu’on n’est pas obligé d’avoir des embeddings pour tous les mots d’une langue (ce qui serait quasi impossible). À la place, l’algorithme WordPiece sépare les mots moins fréquents (comme tokenizer) en bouts de mots (comme to ken izer) et même parfois en lettres. Il se peut donc qu’un texte comporte plus de tokens que de mots (notre exemple a 7 mots et 9 tokens).
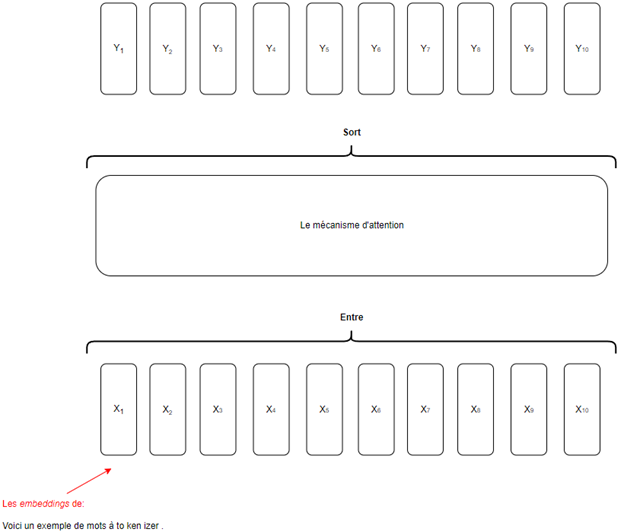
Bref, l’important est de savoir qu’un transformer, en réalité, travaille avec les embeddings des tokens des mots. Cela dit, à partir de maintenant, ces embeddings seront appelés Xi où i est la position du token dans le texte (voir la Figure 1 si ce n’est pas clair).
Figure1 : Entrée et sortie du mécanisme d’attention
À noter qu’il y a un vecteur Y en sortie pour chaque vecteur X en entrée. Donc, Y1 est le match de X2, Y3 de X3, etc. Aussi, les vecteurs en sortie (les Ys) sont de la même taille que les vecteurs en entrée (les Xs). Toutefois, la comparaison se finit là! Puisque les Ys sont ce qu’on appelle des embeddings contextuels. C’est-à-dire qu’ils viennent nuancer le sens de leurs Xs respectifs en ajoutant le contexte de ceux-ci dans leur valeur sémantique.
Et où trouvent-ils ce fameux contexte? Dans les autres mots du texte! Le mécanisme d’attention apprend à porter attention (surprise-surprise) au contexte entourant chacun des embeddings dans le but d’enrichir ceux-ci. D’ailleurs, ce contexte est appelé le score d’attention et il est très intuitif à interpréter. Je vais l’introduire via un exemple.
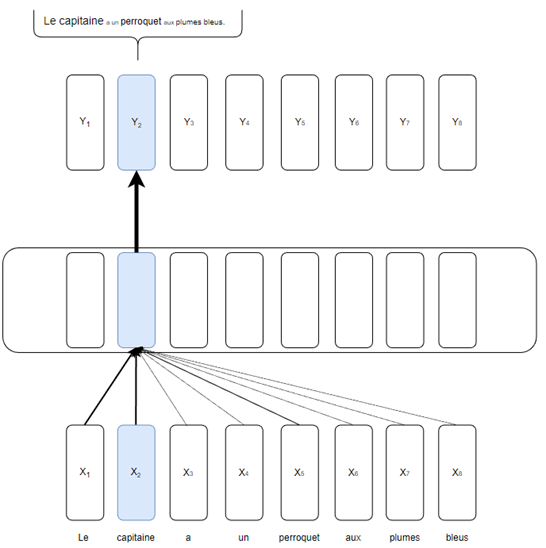
Supposons que j’aimerais calculer l’embedding contextuel (le Y) du token « capitaine » pour la phrase suivante :
Le capitaine a un perroquet aux plumes bleues.
Où on suppose que tous les mots sont des tokens. Alors, le contexte de capitaine pourrait ressembler à quelque chose comme :
Le capitaine a un perroquet aux plumes bleues.
Où les scores d’attention seraient la grosseur des mots (plus le mot est gros, plus il est important au contexte entourant « capitaine »). La Figure 2 schématise le tout.
Figure2: Les scores d’attention de l’exemple
Cette schématisation montre que Y2 contient l’information sémantique du mot qu’il représente (« capitaine »), mais aussi du contexte entourant ce mot. Alors, si ce même mot (« capitaine ») réapparait dans un contexte différent. Disons dans la phrase suivante :
Le capitaine a un « c » sur son chandail.
Alors son Y sera différent du Y2 de la Figure 2, car même s’ils ont le même X au départ, ils ne sont pas utilisés dans le même contexte. Bref, le mécanisme d’attention n’a qu’un seul et unique but, soit d’enrichir les Xs en les transformant (oui oui, j’ai utilisé le mot) en embeddings contextuels (les Ys).Bon, maintenant que l’on comprend ce qui entre et ce qui sort de la machine à saucisse, il est enfin temps de lever le capot et d’examiner le fonctionnement de celle-ci.
Je vous ne cacherai pas que c’est quand même quelque chose de compliqué, alors je vous propose de vous l’expliquer deux fois, la première fois avec les concepts de base et la deuxième en y ajoutant les concepts plus pointus.
Prêt? Je l’espère, parce que ça part.
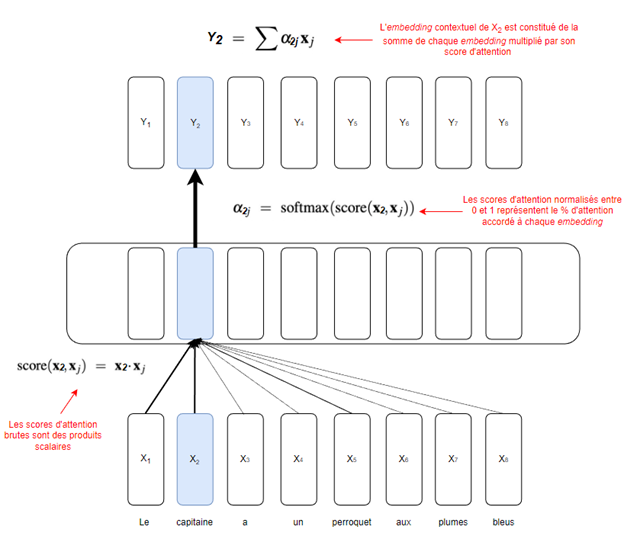
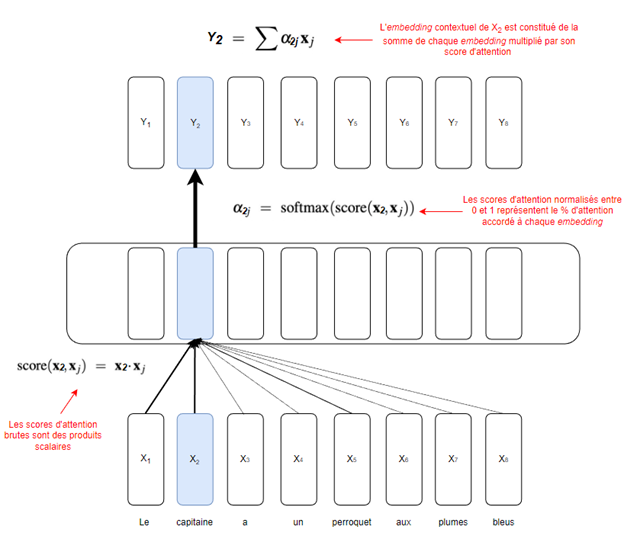
Pour la première, on va se concentrer sur les scores d’attention (la grosseur des flèches dans la Figure 2) en explorant les calculs qui nous ont permis de les déterminer, mais en omettant (pour l’instant) comment on apprend à optimiser ces scores.
Ces scores ne sont rien d’autre que des produits scalaires. Par exemple, calculer le score d’attention entre X2 (l’embedding de « capitaine ») et X5 (l’embedding de « perroquet ») implique de calculer le produit scalaireentre X2 et X5. On en déduit donc que pour déterminer Y2 il va nous falloir tous les scores d’attention liés à X2. Il nous faut donc calculer le produit scalaire entre X2 et tous les autres embeddings du texte, soit les scores d’attention de tous les embeddings par rapport à X2. Ensuite, puisque ces scores peuvent, théoriquement, être entre -∞ et +∞, on les passe dans une softmax, afin de les ramener entre 0 et 1.
On obtient alors une série de scores entre 0 et 1 représentant l’importance des autres mots pour le contexte de X2 (« capitaine »). Par exemple, « Le » pourrait avoir un score de 0.4, « perroquet » de « 0.3 » et « un » de 0.01. Aussi, il est important de spécifier que ces proportions somment à 1. On peut donc voir celles-ci comme un pourcentage d’attention accordé à un embedding. Par exemple, si j’ai 100 % d’attention en banque et que je dois déterminer le contexte entourant le mot « capitaine », alors je pourrais utiliser 40 % de mon attention sur « Le », 30 % sur « perroquet » 1 % sur « un » et le 29 % restant sur les autres tokens. On retrouve alors les fameuses grosseurs de flèche de la Figure 2.
Finalement, l’embedding contextuel de « capitaine » (Y2) n’est rien de plus que la somme de chaque embedding multiplié par son score, son pourcentage d’attention.
Toutes ces étapes sont résumées à la Figure 3.
Figure3 : Schématisation simplifiée du mécanisme d’attention
Félicitations, vous avez réussi à survire à cette première explication du mécanisme d’attention. Pour vous récompenser, je vous ai préparé un petit meme qui, je crois, résume avec humour les derniers paragraphes.
Toutefois, mes lecteurs avec de l’expérience en apprentissage automatique auront remarqué qu’un simple produit scalaire bête et méchant ne permet pas d’apprendre à optimiser les scores d’attention. Je suis d’accord avec eux! Pour qu’un réseau de neurone apprenne, il lui faut des poids à ajuster lors de la rétropropagation du gradient. Le tout, veut malheureusement dire que le vrai calcul des scores d’attention est beaucoup plus compliqué que la version simplifiée présentée à la Figure 3.
Premièrement, chacun des embeddings de mot (les Xi) peut jouer exactement 3 rôles dans le calcul d’attention, soit :
Le rôle de requête si c’est l’embedding pour lequel on essaie de déterminer le Y. Dans notre première explication, l’embedding du mot « capitaine » avait ce rôle.
Le rôle de clé si c’est l’embedding qui est utilisé comme contexte pour déterminer le Y d’un autre mot. Dans notre première explication, les embeddings de « perroquet », « Le » et « un » avaient ce rôle.
Le rôle de valeur lorsqu’il est multiplié par son score d’attention (juste avant le calcul des Ys).
L’intuition est donc qu’un mot devrait avoir des comportements (et donc des embeddings) différents pour chacun de ses rôles. Cela est obtenu via l’introduction de trois nouvelles matrices (WQ, WK et WV) qui représentent respectivement les rôles de requête, de clé et de valeur. D’ailleurs, c’est précisément ces matrices-là qui seront mises à jour lors de la rétropropagation des erreurs.
En ajoutant ces nouvelles informations à la Figure 3, on obtient la Figure 4:
Figure4 : Schématisation du mécanisme d’attention
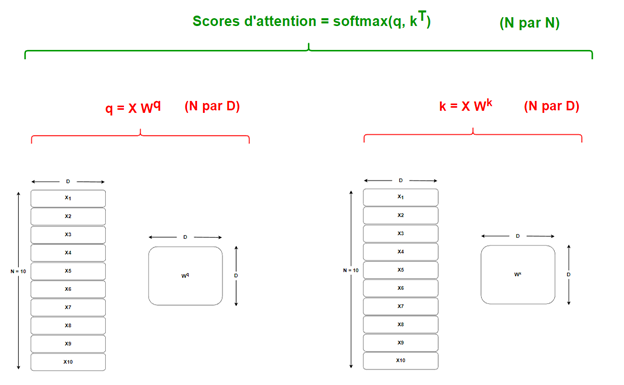
Deuxièmement, puisque les mots sont tous traités indépendamment (traiter X2 ne requiert pas d’avoir préalablement traité X1), tous les Xi peuvent (et donc devraient) être traités en même temps. On les traite en même temps en les empilant pour former une matrice N par D où :
N : Le nombre d’embeddings (Xs) à traiter. On peut aussi le voir comme le nombre de tokens dans mon texte.
D : La taille des embeddings.
Le tout, signifie que les scores d’attention sont représentés par une matrice N par N où chaque ligne représente les poids d’attention accordés et donc doit sommer à 1. Lecteurs plus visuels, ne vous inquiétez pas. Je vous ai concocté une autre œuvre d’art (Figure 5) qui illustre bien ce concept.
Figure5 : Schématisation des calculs matriciels permettant d’obtenir les scores d’attention à partir des vecteurs clé et requête
Troisièmement, parce que tous les mots sont traités en même temps (en parallèle via des calculs matriciels), on perd la position de ceux-ci dans le texte. Pour pallier cette limitation, on vient ajouter N vecteurs appelés embeddings positionnels de manière à pouvoir additionner le ieembedding positionnel au ieembedding d’entrée (Xi).
Voilà! Vous comprenez maintenant, je l’espère, le mécanisme d’attention, soit l’algorithme sur lequel repose l’architecture transformer. Toutefois, on n’est pas encore sortis du bois! Il nous reste quelques concepts à voir avant de pouvoir affirmer bien comprendre cette fameuse architecture. À commencer par le sujet de la prochaine section : l’attention multitête.
L’attention multitête
Je n’élaborerai pas longtemps sur cet aspect de l’architecture, puisque je trouve qu’il est relativement trivial et non essentiel à la compréhension globale de la patente. En somme, dans un transformer, le mécanisme d’attention est encapsulé dans ce qu’on appelle une couche d’autoattention. Dans celle-ci, on passe les embeddings d’entrée (les Xs) dans plusieurs mécanismes d’attentions différents (ils ont tous des Wq, Wk et Wv différents). Ce qui nous donne plusieurs Ys pour chacun de nos Xs. L’intuition derrière ce concept est le suivant : afin de tirer le maximum de contexte de nos Xs, il pourrait être avantageux d’avoir un mécanisme d’attention par type de contexte. Par exemple, pour la phrase suivante :
Quand est-ce que Vincent va décrocher des pirates?
Un mécanisme d’attention pourrait venir, à tort, contextualiser le token « crocher » comme étant un contexte pour « pirate » puisque les pirates ont souvent des crochets et donc que ces tokens sont souvent en relation. On préférerait alors avoir d’autres mécanismes d’attention qui pourraient venir nuancer le contexte global en le ramenant plus vers le fait que Vincent parle beaucoup trop de pirates dans un blogue sur les transformers et que ça commence à devenir gênant. Bref, l’attention multitête introduit une redondance cruciale qui permet d’obtenir des contextes beaucoup plus nuancés qu’une attention simple-tête.
Le bloc de transformation
Bien que la magie des transformers provient de la couche d’autoattention (comprenant l’attention multitête), celle-ci n’est pas la seule couche présente dans l’architecture. Il y a aussi une couche feedforward tel que j’ai introduit dans l’article Le Deep learning, c’est quoi et ça sert à quoi?. La couche feedforward n’a qu’un seul objectif : introduire de la non-linéarité. Finalement, afin d’accélérer la convergence, on ajoute des connexions résiduelles (voir ici si ça ne vous sonne pas une cloche). Pour les visuels, ça se passe à la Figure 6.
Figure6 : Un bloc de transformation
L’architecture transformer
Honnêtement, pas mal tout a été dit! Les transformers sont juste des empilages de blocs de transformation. Par exemple, BERT est composé de 12 blocs de transformation alors que l’encodeur de ChatGPT est composé de 96 blocs de transformation.
Implémentation avec Pytorch
Comme prévu, j’ai pris le temps d’expérimenter avec un mini transformer que j’ai codé uniquement avec Pytorch. Ce transformer est composé de 3 blocs de transformations et a obtenu 75 % de précision en test sur le jeu de données IMDB. Bon, on s’entend qu’on ne repoussera pas l’état de l’art sur ce jeu de données (96 % de précision) avec notre mini transformer, mais là n’est pas le but.
Le code est disponible ici sous la forme d’un notebook.
D’ailleurs, si vous prenez le temps d’ouvrir le notebook, vous noterez que notre transformer est entraîné un peu à la « bonne franquette ». C’est intentionnel. Bref, la seule chose que je veux que vous tiriez du notebook est l’exemple d’implémentation Pytorch des différents concepts discutés tout au long du blogue.
À commencer par la Figure 7, où j’ai implanté un bloc de transformation (Figure 6). À noter que j’y ai ajouté une couche de dropout et deux couches de normalisation afin d’accélérer la convergence et d’éviter le surapprentissage du modèle.
Figure 7 : Notre implémentation d’un bloc de transformation
Ensuite, la Figure 8 montre l’implantation de l’architecture globale du transformer. Celle-ci n’est qu’un empilement de blocs de transformation (dans le notebook, j’en ai empilé 3) et d’une couche linéaire de type feedforward à la fin. Cette dernière ne sert qu’à avoir le nombre de neurones correspondant au nombre de classes du problème (voir l’article déjà cité sur le Deep learning pour plus de détails) sur la dernière couche du classifieur.
Il est aussi à noter notre transformer gère lui-même ses embeddings. Il possède donc un registre de ceux-ci dans lequel le gradient peut se propager lors de la rétropropagation. Il en est de même pour les embeddings de position.
Figure 8 : Notre implémentation d’un transformer servant à faire de la classification de texte.
Conclusion
J’espère sincèrement avoir accompli ma mission de vous familiariser avec le mécanisme d’attention et l’architecture transformer. Dans le cas contraire, ou si vous avez des questions plus précises sur le sujet, je vous invite à me contacter sur LinkedIn. Il me fera plaisir de répondre à vos questions et/ou de discuter avec vous du sujet.
Nous avons à cœur de protéger vos données. Nous utilisons des cookies pour vous offrir une meilleure expérience numérique. En acceptant, vous consentez à notre utilisation de ces cookies.
Fonctionnel
Toujours activé
Le stockage ou l’accès technique est strictement nécessaire dans la finalité d’intérêt légitime de permettre l’utilisation d’un service spécifique explicitement demandé par l’abonné ou l’utilisateur, ou dans le seul but d’effectuer la transmission d’une communication sur un réseau de communications électroniques.
Préférences
Le stockage ou l’accès technique est nécessaire dans la finalité d’intérêt légitime de stocker des préférences qui ne sont pas demandées par l’abonné ou l’utilisateur.
Statistiques
Le stockage ou l’accès technique qui est utilisé exclusivement à des fins statistiques.Le stockage ou l’accès technique qui est utilisé exclusivement dans des finalités statistiques anonymes. En l’absence d’une assignation à comparaître, d’une conformité volontaire de la part de votre fournisseur d’accès à internet ou d’enregistrements supplémentaires provenant d’une tierce partie, les informations stockées ou extraites à cette seule fin ne peuvent généralement pas être utilisées pour vous identifier.
Marketing
Le stockage ou l’accès technique est nécessaire pour créer des profils d’utilisateurs afin d’envoyer des publicités, ou pour suivre l’utilisateur sur un site web ou sur plusieurs sites web ayant des finalités marketing similaires.