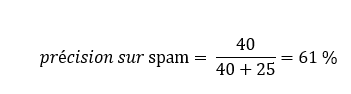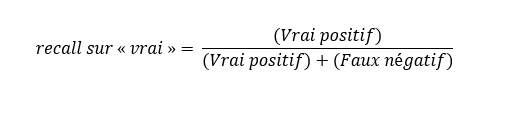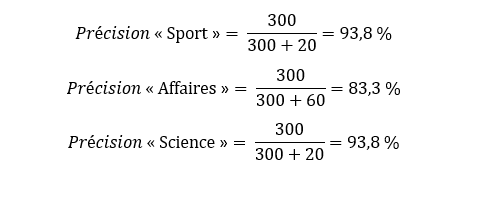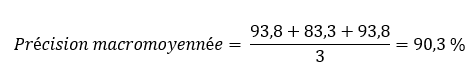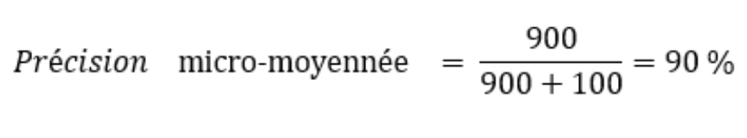Le guide 101 des métriques de performance en classification
Par Vincent Coulombe, 26 octobre 2022
La classification ̶ dans le contexte du Machine Learning ̶ désigne la tâche d’attribuer une ou plusieurs classes à des données. Par exemple, est-ce que ce courriel est un spam ou non. Vous risquez donc d’en entendre parler éventuellement. C’est pourquoi je vous propose aujourd’hui, un guide 101 sur la façon d’évaluer un classificateur afin d’assurer des performances terrain intéressantes par la suite.
On est jeudi après-midi, il fait beau dehors et la fatigue post dîner de restant de pâtes embarque juste au moment où vous vous apprêtez à entrer en réunion avec votre équipe d’Analytics pour jaser des modèles de classification en place. C’est en réalisant que cette réunion n’est qu’un ramassis de métriques les plus obscures les unes que les autres que vous réalisez que votre niveau de fatigue supérieur à ce que vous pensiez avant d’entrer dans la salle. Vous finissez par ressortir de cette rencontre avec un sentiment de soulagement que vous présumez réciproque chez vos collègues sans lunettes.
Fast Foward quelques mois plus tard. Vous vous apercevez que le taux de rejet de votre nouvelle ligne de production automatisée est plus important que prévu pour un produit en particulier. Après une rencontre improvisée avec votre directeur technique, celui-ci vous affirme que vous en avez été avisé lors de la rencontre un jeudi il y a quelques mois.
C’est alors que vous réalisez qu’il vous faudrait peut-être un petit guide pour être capable d’associer les fameux termes techniques ennuyants aux vrais enjeux terrain.
Ça tombe bien! C’est justement ce que je vous propose aujourd’hui! Un guide 101 des différentes métriques d’évaluation de modèles de classification. Un guide visuel en plus! Que demander de mieux?
La classification binaire
La classification binaire est, comme son nom l’indique, une classification en deux classes. Par exemple, la tâche de déterminer si un courriel est un spam ou non est de la classification binaire.
Cela dit, parce que la classification est une tâche dite supervisée, c’est-à-dire qu’on entraîne un classificateur sur des données préalablement étiquetées, il est possible de comparer directement nos prédictions aux étiquettes.
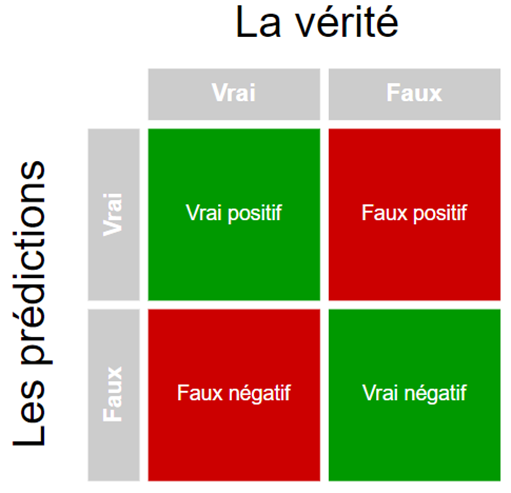
C’est d’ailleurs exactement ce qu’on va faire! En tenant pour acquis que ces étiquettes représentent la vérité, il est possible d’évaluer les prédictions de notre classificateur en les comparant aux étiquettes d’une partie des données qu’il n’a jamais vue en entraînement (dites données de test). D’ailleurs, il est possible de visualiser cette comparaison via une matrice de confusion, où les lignes représentent les prédictions, et les colonnes, les étiquettes (qu’on appellera la vérité). La Figure 1 en est un exemple générique.
Figure 1 : Matrice de confusion binaire. Les prédictions sont verticales et la vérité est horizontale.
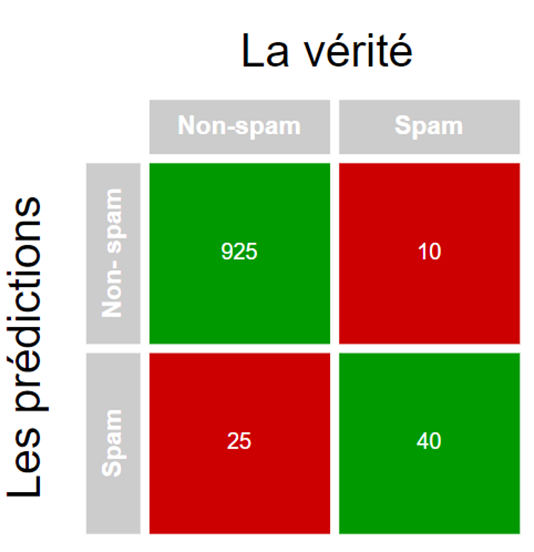
Plus concrètement, disons qu’on cherche à évaluer la performance d’un classificateur de courriels spams. Pour ce faire, on a un jeu de données tests qui contient 1 000 courriels (950 non-spams et 50 spams). On lance alors notre classificateur sur ces données et on obtient la matrice de confusion présentée à la Figure 2.
Figure 2 : Matrice de confusion sur 1000 courriels (950 non-spams et 50 spams)
L’accuracy
En regardant la matrice de confusion à la Figure 2, il est possible de constater que notre classificateur a réussi à prédire correctement 925 non-spams et 40 spams. Pour un total de 965 bonnes prédictions sur 1 000 courriels ou une accuracy de 96,5 %!
C’est là qu’un œil non aiguisé dans l’art de déceler les shows de boucane pourrait se dire « 96,5 % d’accuracy, c’est excellent! », mais pas vous. Du moins pas après votre lecture passionnée de ce blogue! En effet, les 2 classes (non-spams et spams) sont excessivement débalancées (950 vs 50). Ce qui veut dire qu’il est vachement plus payant pour notre classificateur de prédire non-spam que le contraire. C’est comme si je devenais un concurrent dans un jeu télévisé où je devais répondre Vrai ou Faux aux questions. Eh bien si 95 % des bonnes réponses sont Vrai, j’ai tout intérêt à y penser à deux fois avant de répondre Faux!
D’ailleurs, suivant cette logique, le débalancement entre nos classes (950 non-spams et 50 spams) implique qu’un classificateur qui ne ferait que prédire non-spam aurait 950 bonnes prédictions sur 1 000 courriels. Ce qui correspond à une outrageuse accuracy de 95 %!
Bref, tout ça pour dire que si jamais vous avez un débalancement entre vos classes, l’accuracy va vous être aussi utile qu’un lecteur à cassette en 2022! Heureusement, il existe d’autres métriques d’évaluation.
La précision
Reprenons mon analogie du quiz télévisé Vrai ou Faux (mon rêve). Alors, ma précision sur Vrai serait ma proportion de bonnes réponses quand je réponds Vrai. Ce qui veut dire que, si je veux une bonne précision sur vrai, il faut que je sois sûr de mon coup avant de répondre Vrai à une question! Parce que si je me trompe, je perds de la précision.
Bref, cette métrique vient mesurer ma capacité à ne pas répondre n’importe quoi sur une classe en particulier. Donc, si vous avez une classe sur laquelle vous ne voulez particulièrement pas vous tromper lorsque vient le temps de prédire dessus, portez attention à son niveau de précision!
Par exemple, il s’avère que notre super classificateur n’a pas tendance à être super bon lorsqu’il prédit qu’un courriel est un spam :
En effet, 39 % des courriels classifiés comme spams, n’en sont pas! Ouch!
Le recall
Toujours dans notre bon vieux jeu télévisé, je suis maintenant à la dernière question du quiz. Celle qui vaut 1 million de dollars! Juste avant de l’énoncer, l’animateur me mentionne que je ne vais avoir que 60 secondes pour y répondre. La nervosité est à son comble! Après avoir entendu la question, je crois connaitre la réponse, mais je n’en suis pas certain. J’hésite. C’est alors que j’entends le buzzer qui sonne. J’ai été trop lent! Et c’est pendant que l’animateur donne la réponse que je réalise que je la savais! Mon premier réflexe : vouloir recommencer, vouloir un recall de la question.
Le but de cette magistrale mise en situation était de vous mettre dans le bon état d’esprit pour parler du recall. Je l’appelle la métrique du regret. De ce fait, elle mesure, pour une classe, la proportion de la vérité qui a été prédite correctement.
Bref, s’il y a une vérité que je ne veux absolument pas échapper, j’ai intérêt à porter attention à son recall. Suivant cette logique, il est possible de se rendre compte que notre classificateur de courriels laisse passer beaucoup de spams. En effet, son recall sur ceux-ci étant de :
Ce qui veut dire que 20 % des spams sont indétectés! Re-ouch!
Le F1
À ne pas confondre avec la F1 (vroom vroom!), Le F1 est simplement la moyenne harmonique de la précision et du recall.
La question que vous vous posez : depuis quand mélange-t-on des instruments de musique aux métriques statistiques? Ma réponse : je n’en ai aucune idée!
Par contre, la moyenne harmonique, ça, je sais ce que c’est! En gros, c’est une moyenne, mais avec une petite twist pour être plus efficace avec des ratios.
Le F1 est donc utilisé lorsqu’on cherche un compromis entre la précision et le recall. Autrement dit, on cherche à prendre notre temps pour ne pas répondre n’importe quoi sur une classe, mais en même temps on ne veut pas être trop hésitant pour ne pas échapper une opportunité de prédire la vérité.
La classification multiclasse
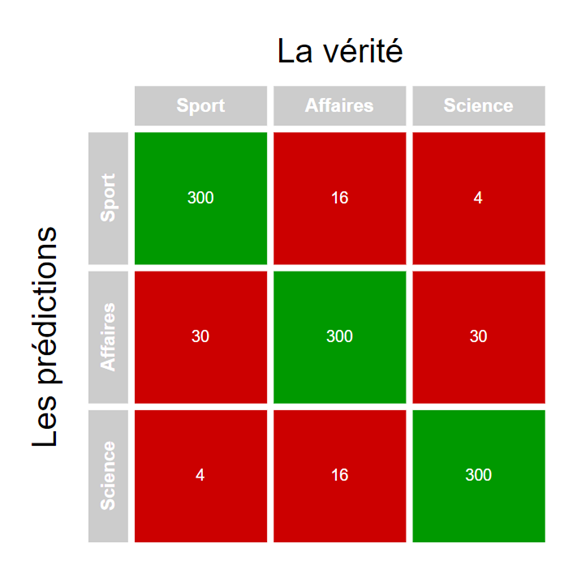
On parle de classification multiclasse lorsqu’on a plus de deux classes. Par exemple, si on cherche à classer des textes en fonction de leurs sujets. Ce faisant, il est possible d’utiliser une matrice de confusion comme à la Figure 3 pour 1 000 textes portant sur le sport, les affaires et la science.
Figure 3 : Matrice de confusion sur 1 000 textes portant sur le sport, les affaires et la science
Il est possible de constater que la matrice est plus imposante et soudainement plus difficile à interpréter (je vous laisse vous imaginer le casse-tête lorsqu’il y a 10 classes). C’est alors que nos fameuses métriques (accuracy, précision, recall et F1) prennent toute leur valeur car elles nous permettent de déterrer les résultats ensevelis sous ces grosses matrices.
De plus, il est possible de réduire cette grosse matrice en 3 sous-matrices binaires, soit une par classe. Voir la Figure 4 pour visuel.
Figure 4 : Matrices de confusion binaires respectives à chaque classe
De ces nouvelles matrices, il est possible de calculer les métriques expliquées plus haut. Par exemple, ici on a :
En faisant la moyenne des trois précisions on obtient :
On dit alors que notre classificateur a 90,3 % de précision macro-moyennée, soit la moyenne de la précision des trois sous-matrices. Comme vous pouvez vous en douter, maintenant que vous avez l’œil aiguisé, on utilise les métriques macro-moyennées lorsqu’il y a un débalancement entre nos classes.
Finalement, il existe une 4e sous-matrice. Celle qui correspond à la somme des 3 présentées à la Figure 4, soit :
Figure 5 : Somme des trois matrices de la Figure 4
Calculer la précision de cette sous-matrice revient à calculer la précision micro-moyennée, soit :
À noter que les métriques micro-moyennées sont utiles lorsqu’on cherche à voir les performances globales de notre classificateur. Personnellement, je les trouve moins parlantes, car elles peuvent « cacher » des performances faibles sur des classes sous-représentées (un peu comme l’accuracy). Pour cette raison, j’ai tendance à leur préférer les métriques macro-moyennées.
Conclusion
On est jeudi après-midi, vous avez encore trop mangé de pâtes ce midi et ça commence à jouer avec votre niveau de motivation au moment où vous entrez en réunion avec votre équipe d’Analytics pour jaser des modèles de classification en place. Ça part. L’équipe présente quelques matrices de confusion puis vante l’accuracy de son modèle… vous froncez les sourcils. Vous savez de quoi ils parlent, mais surtout, vous savez quelles questions poser et quelles métriques challenger. De plus, alors que vos collègues s’endorment et se demandent ce qui se passe, vous réalisez que vous constituez la dernière ligne de défense entre un modèle inefficace et votre chaîne de production. Le niveau de motivation remonte. Vous êtes prêt!
Gérer le consentement aux témoins
Nous avons à cœur de protéger vos données. Nous utilisons des cookies pour vous offrir une meilleure expérience numérique. En acceptant, vous consentez à notre utilisation de ces cookies.
Fonctionnel
Toujours activé
Le stockage ou l’accès technique est strictement nécessaire dans la finalité d’intérêt légitime de permettre l’utilisation d’un service spécifique explicitement demandé par l’abonné ou l’utilisateur, ou dans le seul but d’effectuer la transmission d’une communication sur un réseau de communications électroniques.
Préférences
Le stockage ou l’accès technique est nécessaire dans la finalité d’intérêt légitime de stocker des préférences qui ne sont pas demandées par l’abonné ou l’utilisateur.
Statistiques
Le stockage ou l’accès technique qui est utilisé exclusivement à des fins statistiques.Le stockage ou l’accès technique qui est utilisé exclusivement dans des finalités statistiques anonymes. En l’absence d’une assignation à comparaître, d’une conformité volontaire de la part de votre fournisseur d’accès à internet ou d’enregistrements supplémentaires provenant d’une tierce partie, les informations stockées ou extraites à cette seule fin ne peuvent généralement pas être utilisées pour vous identifier.
Marketing
Le stockage ou l’accès technique est nécessaire pour créer des profils d’utilisateurs afin d’envoyer des publicités, ou pour suivre l’utilisateur sur un site web ou sur plusieurs sites web ayant des finalités marketing similaires.