Microsoft OneLake dans Fabric : pour appuyer la vision d’unifier les données d’une organisation
Par Frédérick Samson, 4 octobre 2023
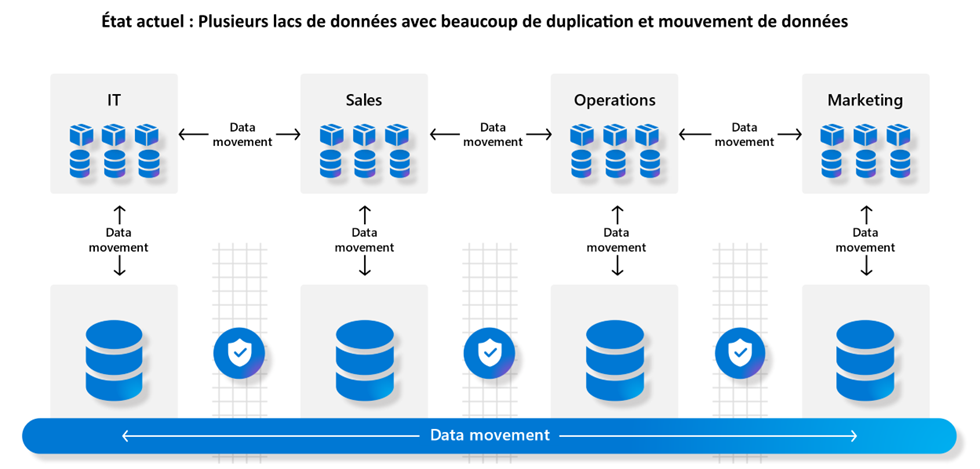
[ Microsoft OneLake ] Plusieurs organisations ont investi pour centraliser leurs données dans un lac, afin de briser les silos et faciliter le croisement des données, les analyses, la sécurité, la gouvernance et la découverte des données. Malheureusement, avec les technologies existantes, l’objectif n’est pas toujours atteint et le résultat est qu’il y a plusieurs duplications des données, donc plusieurs mouvements de données.
Avec OneLake, Microsoft vise à permettre la réalisation de la vision en offrant un seul lac de données logique à l’échelle de l’organisation, avec une seule copie des données et un modèle de sécurité natif s’appliquant à tous les engins (à venir).
Pour concrétiser cette vision, Microsoft s’appuie sur les caractéristiques suivantes :
Un seul lac de données logique par organisation
Des raccourcis afin d’éviter la duplication et les mouvements de données
Un format de stockage unique et supporté par tous les engins (Spark, T-SQL, KSQL et Analysis Services)
Une plate-forme ouverte
1. Chaque organisation dispose d’un seul OneLake Un peu comme chaque organisation a son tenant Power BI, un OneLake est automatiquement disponible. Les espaces de travail Fabric sont le premier niveau de découpage dans le lac unifié. L’introduction récente des domaines permet de les regrouper logiquement ensemble.
Illustration d’un OneLake organisé en trois domaines (Sales, Marketing, Finance) chacun ayant une série d’espaces de travail.
Seuls les espaces de travail sous capacité Fabric/Premium apparaîtront dans l’explorateur OneLake
Ainsi les espaces de travail ne contenant que des artefacts Power BI ne sont pas considérés comme faisant partie de OneLake.
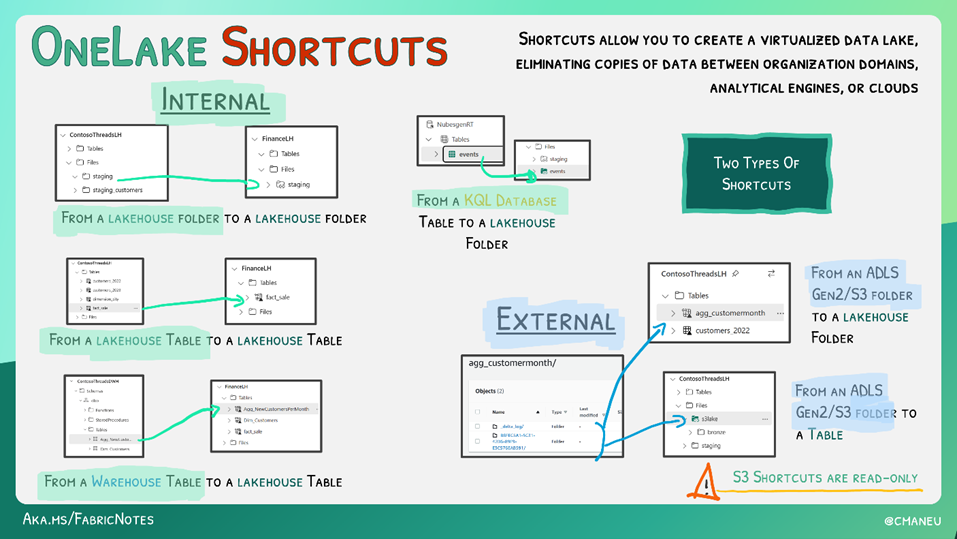
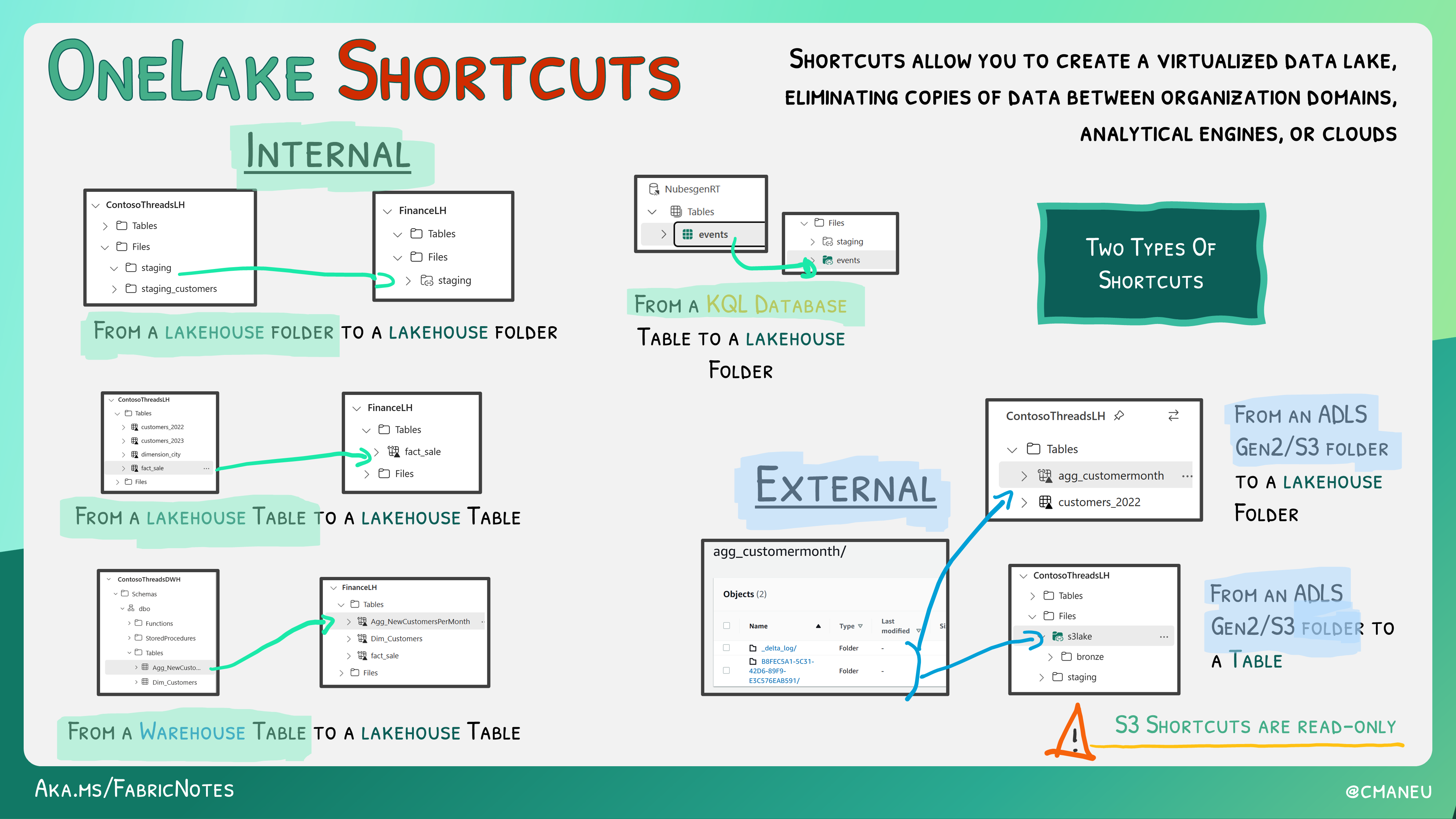
2. Les raccourcis permettent d’éviter la duplication et les mouvements de données
Les mêmes données sont souvent utilisées par plusieurs fonctions (Marketing, Ventes, RH, etc.) d’une organisation. Avec l’introduction des raccourcis dans Microsoft Fabric, il est possible d’ingérer une seule fois les données et de les utiliser à répétition sans avoir à dupliquer l’information.
Illustration : Plutôt que d’avoir à copier des données RH pour les utiliser pour un tableau de bord Finance, il est possible d’utiliser un raccourci sans mouvement de données.
Un raccourci peut être interne à Fabric, mais aussi externe en référant à des données stockées dans un Azure Storage Account (ADLSv2) ou Amazon S3 sans impact sur la performance.
Les détails sur ce qu’il est actuellement possible de faire avec les raccourcis sont bien illustrés dans cette image de https://microsoft.github.io/fabricnotes/
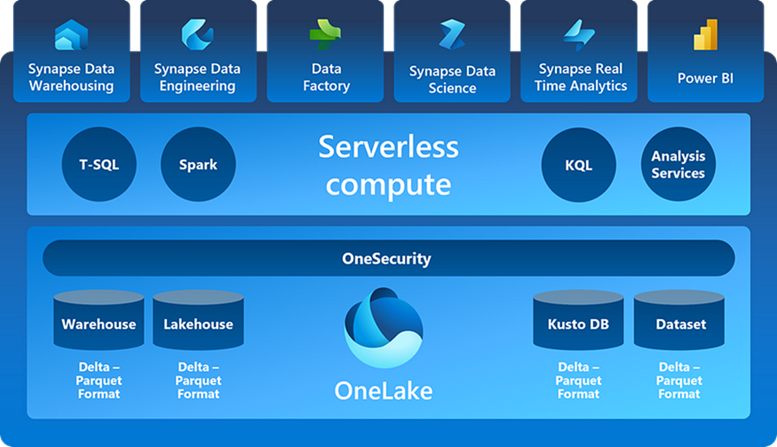
3. Un seul format de stockage supporté par tous les engins
Peu importe l’outil utilisé pour ingérer et transformer les données (Spark, Dataflows, T-SQL), le format sous-jacent sera toujours des fichiers Delta-Parquet optimisés pour Power BI. La sécurité n’est pas encore disponible, mais la vision est de pouvoir la définir à un seul endroit. En favorisant un seul format de fichier, on évite la duplication de données dans le seul but d’utiliser un outil différent. Auparavant, les lacs de données étaient souvent remplis d’une panoplie de formats de fichiers (CSV, JSON, AVRO, Parquet, ORC, etc.). Et c’est sans compter les formats propriétaires pour les bases de données relationnelles (ex. Synapse SQL Dedicated Pool) et multidimensionnelle (ex. jeu de donnés Power BI en mode Import).
Tous les engins (« Serverless compute ») sont capables de travailler avec le format Delta-Parquet privilégié dans Microsoft Fabric. Il est tout de même possible d’ingérer des données dans leur format brut (ex. CSV, Json), afin de les convertir en Delta-Parquet.
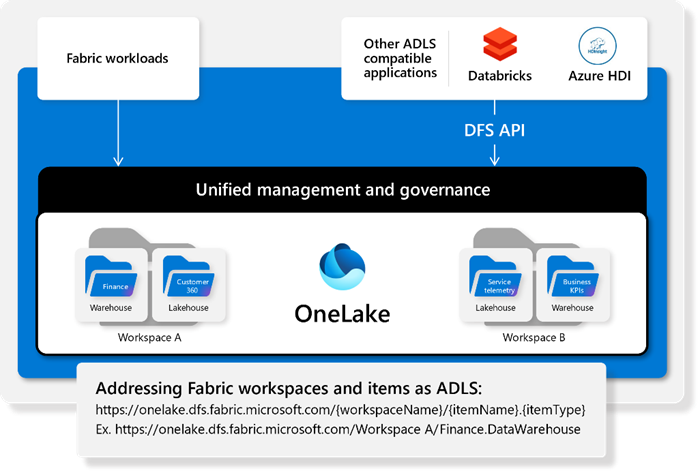
4. Une plate-forme ouverte
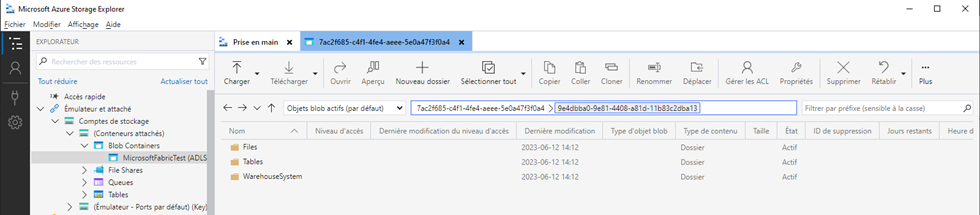
OneLake est compatible avec les APIs et SDKs d’Azure Data Lake Storage Gen2 (ADLSv2) ce qui permet à des outils tierces parties d’accéder aux données. Par exemple, une organisation qui utilise Databricks pourrait accéder à OneLake comme s’il s’agissait d’un seul compte de stockage. Chaque espace de travail sous capacité Fabric sera perçu comme étant un « container » ADLSv2.
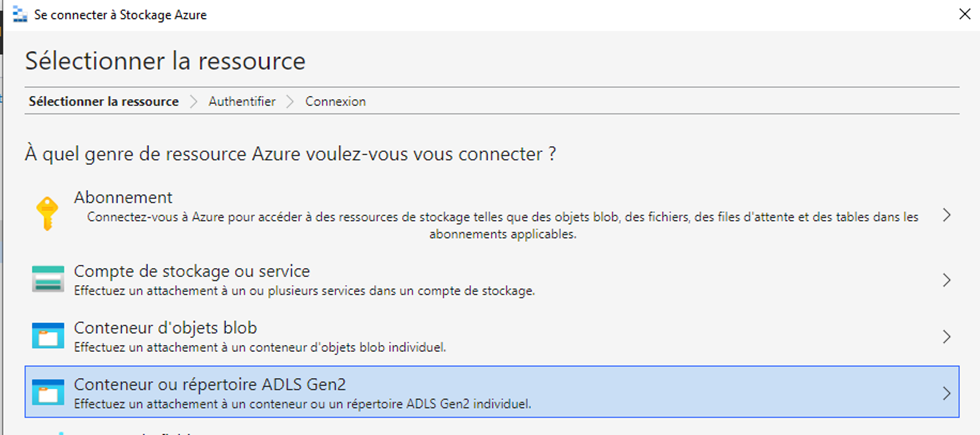
Un outil comme Microsoft Azure Storage Explorer est capable de visualiser le contenu de OneLake :
Il faut utiliser une adresse dans ce format : https://onelake.dfs.fabric.microsoft.com/{workspace-Name}/{itemName.itemType}/
Dans mon cas, comme l’espace de travail avait des espaces « Microsoft Fabric Test », j’ai dû utiliser le GUID au lieu du nom.
Cet article donne beaucoup plus de détails sur l’utilisation de Microsoft Azure Storage Explorer avec OneLake.
Mot de la fin
Nous avons vu les différentes caractéristiques de Microsoft Fabric qui, à mon avis, offrent le potentiel de concrétiser la vision de centraliser les données et d’éviter la duplication et les mouvements de données.
Finalement, il y aura évidemment un coût pour utiliser un tel service. Ce sera probablement facturé au volume de stockage (similaire à ADLSv2) mais ce n’est pas encore annoncé officiellement. Cette page détaillera tous les coûts et contient actuellement le prix pour les différentes capacités Fabric.
Vous en savez maintenant plus sur OneLake dans Microsoft Fabric. J’explorerai d’autres aspects de cette plate-forme dans de prochains articles.
Gérer le consentement aux témoins
Nous avons à cœur de protéger vos données. Nous utilisons des cookies pour vous offrir une meilleure expérience numérique. En acceptant, vous consentez à notre utilisation de ces cookies.
Fonctionnel
Toujours activé
Le stockage ou l’accès technique est strictement nécessaire dans la finalité d’intérêt légitime de permettre l’utilisation d’un service spécifique explicitement demandé par l’abonné ou l’utilisateur, ou dans le seul but d’effectuer la transmission d’une communication sur un réseau de communications électroniques.
Préférences
Le stockage ou l’accès technique est nécessaire dans la finalité d’intérêt légitime de stocker des préférences qui ne sont pas demandées par l’abonné ou l’utilisateur.
Statistiques
Le stockage ou l’accès technique qui est utilisé exclusivement à des fins statistiques.Le stockage ou l’accès technique qui est utilisé exclusivement dans des finalités statistiques anonymes. En l’absence d’une assignation à comparaître, d’une conformité volontaire de la part de votre fournisseur d’accès à internet ou d’enregistrements supplémentaires provenant d’une tierce partie, les informations stockées ou extraites à cette seule fin ne peuvent généralement pas être utilisées pour vous identifier.
Marketing
Le stockage ou l’accès technique est nécessaire pour créer des profils d’utilisateurs afin d’envoyer des publicités, ou pour suivre l’utilisateur sur un site web ou sur plusieurs sites web ayant des finalités marketing similaires.













{kind=link}