Décrypter le NLP (2e partie) : les réseaux de neurones récurrents
Par Vincent Coulombe, 25 janvier 2023
Cela fait maintenant quelques années que la progression du NLP passe par le Deep Learning. Ce long délai, lorsqu’on prend le temps d’y penser, origine d’un seul et unique fait : le langage naturel est complexe parce qu’il permet aux humains de s’exprimer librement et qu’ils sont eux-mêmes complexes. Dix personnes pourraient écrire des textes complètement différents sur un sujet aussi simple que la critique du dernier film de Batman (super bon, en passant).
D’ailleurs, pendant des années, de brillants chercheurs ont essayé de comprendre et de capturer toute cette complexité sémantique. Soit à l’aide de codex tels que WordNet et de systèmes à base de règles ou de systèmes génératifs. Somme toute, si chacune de ces méthodes permettait ultimement de générer des modèles avec un fort niveau de précision, la richesse du langage est telle qu’ils ne pouvaient garantir un bon niveau de rappel (voir mon autre article sur les métriques de classification).
Bref, sans réécrire la première partie de cet article, les techniques de NLP n’ont eu d’autre choix que de tranquillement se complexifier à mesure qu’une nouvelle technique venait pallier les faiblesses de ses prédécesseures.
Ce qui nous amène où on s’était laissés à la fin du précédent article, soit les word embeddings. Où nous avions tiré la conclusion logique que ces vecteurs permettent, en théorie, une meilleure analyse qu’un simple bag-of-words naïf, sans toutefois être parfaits. Notamment :
Garder à l’esprit qu’un word embedding d’une longueur X (disons 300 comme GloVe) pour chaque mot d’un dictionnaire est extrêmement coûteux en mémoire (ce qui m’a d’ailleurs contraint à changer mon ordinateur à l’époque)
Chaque mot de notre dictionnaire ne contient qu’un seul word embedding. Ce qui pose évidemment un problème pour un mot à plusieurs sens (café, nature solide, etc.) dont la valeur sémantique peut être très variable selon le contexte dans lequel il est utilisé.
De plus, j’avais spécifié que les word embeddings étaient utilisés conjointement avec des réseaux feed forward. Ce qui générait des résultats intéressants à l’époque, mais avait un défaut majeur : la taille du vecteur à l’entrée du réseau était trop grande! En effet, afin de pouvoir traiter un simple texte de 50 mots représenté par des word embeddings comme GloVe, il nous faudrait un vecteur d’entrée de 15 000 (soit 50 vecteurs de taille 300)! Ce qui est évidemment impossible en pratique. Les chercheurs de l’époque n’ont donc pas eu le choix de tourner les coins ronds. Et la meilleure méthode qui fonctionnait était celle de simplement additionner les représentations des mots d’un texte. La taille du vecteur d’entrée était donc toujours constante (par exemple, 300 avec GloVe).
Cependant, cette méthode générait un nouveau problème : il est impossible pour le réseau de savoir l’ordre des mots dans le texte. Il ne connait que la somme des valeurs sémantiques de ceux-ci. Ce qui, on s’en doute, le handicape fortement lors de l’exécution de plusieurs tâches.
Heureusement, nous avons trouvé une solution à ce problème. Soit (roulement de tambour…), vous l’aurez deviné, les réseaux récurrents! En effet, ceux-ci permettent de garder la richesse sémantique des word embeddings ET de traiter les mots séquentiellement de manière à pouvoir apprendre les relations entre eux. Ces réseaux ont notamment permis l’émergence de systèmes de d’analyse de sentiment et de classification plus puissants, mais ont aussi révolutionné les domaines de l’extraction d’information et de l’analyse grammaticale. Soit des tâches où nous devons prendre une décision à chaque mot (analyse séquentielle).
Le RNN
Comme mentionné précédemment, afin d’être en mesure de faire de l’analyse séquentielle, il nous faut une architecture adaptée capable d’inférer sur chaque mot et, idéalement, de se souvenir des mots précédents et de la prédiction sur ceux-ci. Par exemple, si je désire trouver le groupe grammatical du mot « excellent » dans la phrase suivante :
Ils excellent.
Si je sais que celui-ci est précédé de « Ils », prédit comme étant un pronom, alors il devient beaucoup plus facile de déterminer qu’« excellent » est un verbe. Aussi, si je désire effectuer la même tâche pour la phrase suivante :
Il est excellent.
Alors, sachant qu’il est précédé de « est » qui est un verbe m’impose à changer ma prédiction. Dans ce cas-ci, je devrais être en mesure de déterminer qu’il s’agit d’un adjectif. Bref, il s’agit là de l’intuition derrière les réseaux récurrents. Utiliser l’information passée et présente pour pouvoir prendre la meilleure décision possible.
Mais concrètement, ça ressemble à quoi cette affaire-là, me direz-vous. Eh bien pour y arriver, je vous propose de commencer par notre bon vieil ami, le réseau Feed Forward.
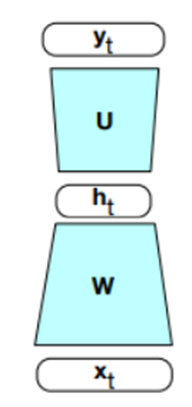
Figure 1 : Un réseau Feed Forward avec 1 couche cachée
Où xt représente le vecteur d’entrée, ht représente la couche cachée, yt représente la couche de sortie, W représente la matrice des poids entre xtet htet U représente la matrice des poids entre ht et yt. Nous retrouvons donc exactement l‘architecture vulgarisée dans l’article de blogue sur le Deep Learning mentionné au début de ce texte.
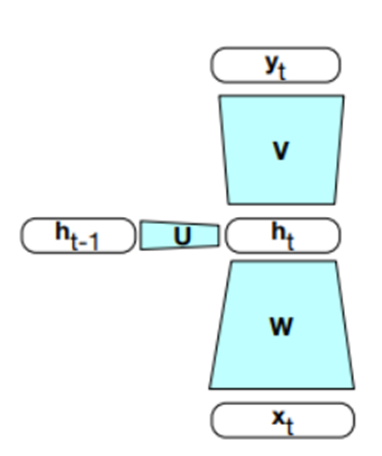
Sachant cela, il est possible de schématiser l’architecture d’un réseau récurrent comme ceci :
Figure 2 : Un réseau récurrent
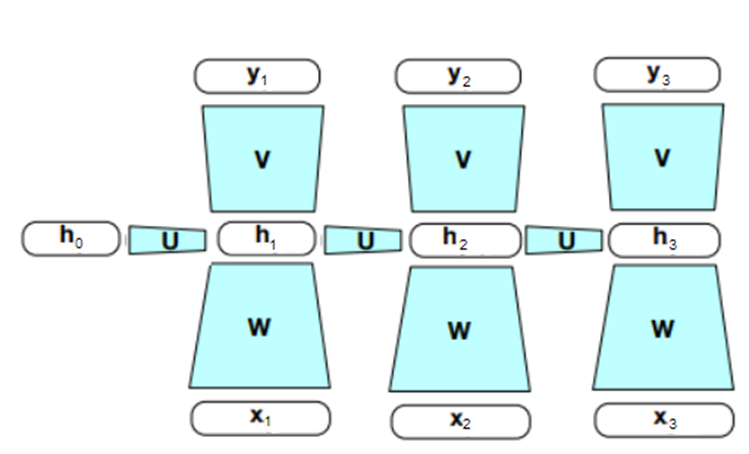
Où on se sert de l’information condensée dans la couche cachée du mot précédent (t-1) EN PLUS de l’information condensée dans la couche cachée du mot actuel (t). C’est tout! Il ne reste plus qu’à promener le réseau de la Figure 2 sur tous les mots du texte pour générer une sortie y pour chacun d’eux. Ce qui veut dire que seules les formes blanches dans la Figure 2 changent de mot en mot, les matrices W, V et U sont EXACTEMENT les mêmes pour tous les mots du texte.
Figure 3 : On promène le réseau récurent sur un texte de trois mots (x1, x2, x3)
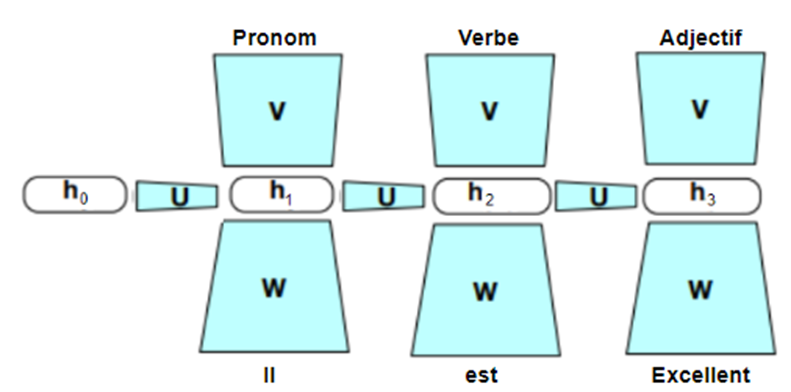
Donc, concrètement, si on passe un réseau récurrent sur la phrase d’introduction à la section, on obtient quelque chose comme ce qui est présenté à la Figure 4 :
Figure 4 : Passer un réseau récurrent sur la phrase « Il est excellent »
Bref, c’est juste ça! Bon j’avoue qu’il existe une panoplie de tours de passe-passe qui peuvent complexifier la patente, mais à la base, un réseau récurrent c’est ça. D’ailleurs, parlant de tours de passe-passe, il est possible d’améliorer le réseau récurrent de base (recurrent neural network ou RNN) en lui donnant de meilleurs outils afin de l’équiper pour faire face à différents types de problèmes. Sachant cela, les prochaines sections porteront sur quelques-uns de ces outils ainsi que sur des problèmes qu’ils aident à résoudre. Finalement, il est à noter que ces outils peuvent tous être combinés pour former un réseau récurent « full equip ».
Le CRF
Le premier outil que je vous propose est le CRF ou conditionnal random field qui est un algorithme de programmation dynamique (souvent une variante de l’algorithme de Viterbi). Cet outil est utilisé en analyse de séquence (comme l’analyse grammaticale) comme couche redondante de prise de décision. Le tout afin de pouvoir faire un lien entre les prédictions faites à chaque mot.
Je crois que ça va être plus clair avec un exemple. Supposons que j’aimerais faire l’analyse grammaticale de notre phrase adorée, soit :
Il est excellent.
Eh bien, il se pourrait (dépendamment de la manière qu’il a été entraîné) que notre réseau prédise qu’ « excellent » est un verbe même s’il sait (via h1) que « est » est aussi un verbe. Donc, afin de s’assurer que notre réseau ne commet pas de telles erreurs, on ajoute une redondance sur la prise de décision (le CRF). Celui-ci vient alors réfuter la prédiction en lui spécifiant qu’il est fortement improbable que le verbe « excellent » suive le verbe « est ». Alors le réseau lui retourne sa 2e meilleure prédiction. Soit que « excellent » est un adjectif. Et alors le CRF est d’accord pour dire que l’adjectif « excellent » suive le verbe « est ».
Bref, j’aime voir cette dynamique comme celle d’un professionnel et de son stagiaire. Où le professionnel (le CRF) n’a pas le temps de faire le travail (évaluer optimalement toutes les combinaisons possibles est trop couteux d’un point de vue computationnel), alors il le délègue à un stagiaire (le RNN) qu’il supervise et corrige au besoin.
La bidirection
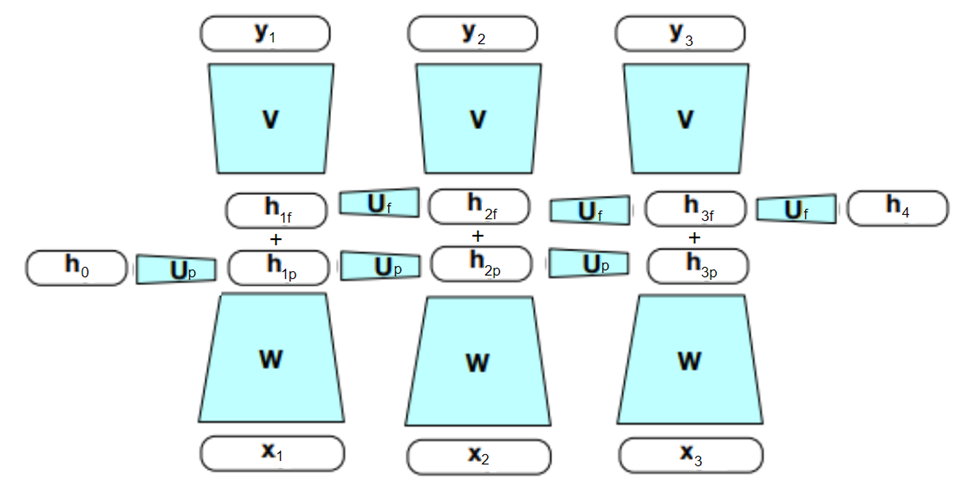
Le deuxième outil à ajouter au coffre de notre RNN est celui de la bidirection. C’est-à-dire qu’on va chercher le contexte des mots futurs, en plus de celui des mots précédents. Notre contexte a alors deux directions (ppour le contexte passé et f pour le contexte futur). On additionne alors simplement les états cachés p et f pour tenir compte des contextes passés et futurs, soit :
Figure 5 : Le Bi-RNN
Bon, maintenant qu’on sait ce qu’est la bidirection, il ne reste plus qu’à déterminer dans quel contexte elle peut être utile. Supposons que j’ai la phrase suivante :
Lit-il présentement?
On s’entend pour dire que si j’utilise le réseau unidirectionnel de la Figure 3, je possède très peu d’information contextuelle pour me prononcer sur le groupe grammatical du mot « Lit ». Est-ce un nom (comme un lit) ou bien est-ce un verbe (comme je lis). Dur à dire… Toutefois, si je pars de la fin, je vois clairement que « Lit » est un verbe. Il peut donc (parfois) être utile d’analyser une phrase dans les deux sens.
Le LSTM
Je ne vous cacherai pas que j’ai gardé l’outil le plus compliqué pour la fin. Soit, le LSTM ou Long Short Term Memory qui a été créé pour un seul but : pallier la plus grande faiblesse des RNN. Faiblesse que j’ai délibérément omis de mentionner jusqu’ici parce que je la réservais pour cette section du blogue.
Si on regarde attentivement les Figures 3 et 4, on se rend compte que nos couches cachées h sont modifiées à chaque fois qu’on passe un nouveau mot dans notre réseau. Par exemple, lorsque notre réseau traite x1on ajoute la sortie du W lui correspondantà celle de la matrice U correspondant à h0 pour obtenir h1. H1devient donc un hybride entre le contexte du mot et le contexte passé. Ce qui veut dire qu’après 5, 10 ou 15 mots, il ne reste plus grand-chose de h1 puisque celui-ci a été « écrasé » par 5, 10 ou 15 autres h et x. Bref, ce mécanisme intrinsèque rend les RNN très mauvais sur des textes longs.
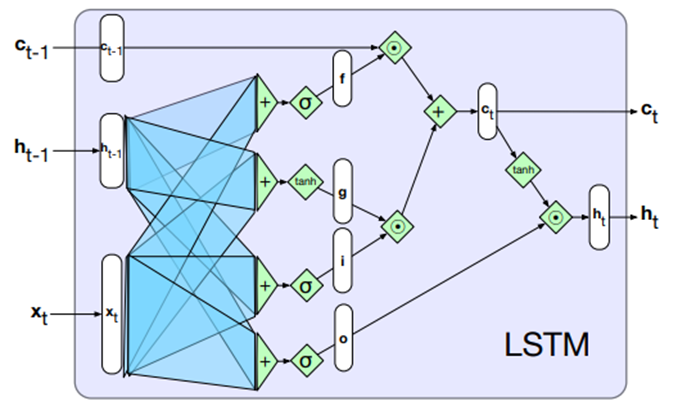
Pour pallier cette erreur, on introduit les concepts de mémoire longue et de mémoire courte. Où la mémoire courte n’est que notre h présenté aux Figures 3 et 4 et la mémoire longue est un nouveau vecteur c qui est seulement mis à jour quand le réseau juge que ça en vaut la peine. Cela dit, notre réseau a alors trois sources d’information, soit :
x : La valeur sémantique du mot actuel
h : La mémoire à court terme (le contexte des 2-3 mots précédents)
c : La mémoire à long terme (le contexte général du texte à analyser)
Sachant cela, la magie opère quand on laisse au réseau le luxe de pouvoir choisir sur quoi se baser pour faire son analyse. Ainsi, s’il juge que le mot actuel a peu de valeur sémantique (par exemple : c’est une préposition comme à, de, pour, sur, etc.), il peut décider de ne pas trop se servir de x pour l’analyse et de plus se fier sur h et c. Et si on est en début de phrase, il risque plus de se fier sur h. Alors qu’en fin de phrase, c risque d’être une source d’information plus sure.
D’ailleurs, ce fameux luxe de choisir est souvent appelé gate dans la littérature. Il s’agit de trois vecteurs (f, i et o), dont les poids sont ajustés à l’entrainement, qui permettent de laisser passer plus ou moins l’information contenue dans c, x et h respectivement.Le tout, bien sûr agrémenté de quelques fonctions d’activations, est présenté à la Figure 6
Figure 6 : Le LSTM
Conclusion
J’espère qu’à la suite de votre lecture de cet article vous avez été en mesure de prendre conscience de la puissance d’un Bi-LSTM-CRF (qui était l’état de l’art en NLP en 2017). Mais surtout, de comprendre comment on utilisait ces réseaux pour créer des liens entre les word embeddings des mots d’une phrase afin de pallier les faiblesses des réseaux feed forward. Bref, quoi vouloir de plus?
Eh bien figurez-vous que notre fameux Bi-LSTM-CRF, aussi bon soit-il, est loin d’être parfait! Plus précisément, il possède les deux gros défauts suivants :
Le réseau ne voit pas directement les relations entre les mots. En effet, il passe plutôt par les vecteurs h (pour les relations voisines) et c (pour les relations éloignées)pour faire son analyse. Le tout, peut rendre certains liens plus ou moins nébuleux aux yeux du réseau et le mener à prendre de mauvaises décisions dans certains contextes. Il faudrait donc trouver une manière de représenter plus directement ces liens entre les mots.
Par sa définition, le réseau de neurones récurrents doit faire une forward pass complète sur chacun des mots d’un texte lors de son analyse de celui-ci. Ce traitement séquentiel rend donc l’inférence (et donc aussi l’entraînement) de ces modèles très couteuse d’un point de vue computationnel. Il faudrait donc trouver un moyen de pouvoir traiter parallèlement les mots, tout en gardant l’information positionnelle de ceux-ci.
En somme, vous devez commencer à voir un pattern émerger ici : nous avons dû trouver de nouvelles techniques pour venir pallier les faiblesses de notre ami le Bi-LSTM-CRF. Ce qui nous amène en 2017 ou une équipe de chercheurs de Google a publié l’article Attention is all you need décrivant en détail une nouvelle architecture de réseau de neurones conçus spécialement pour conserver les forces du Bi-LSTM-CRF tout en atténuant considérablement ses faiblesses! C’est d’ailleurs sur le mécanisme d’attention introduit dans cet article que les gros transformers modernes comme BERT (encodeur) ou GPT (décodeur) reposent.
Toutefois, m’étant déjà étalé plus qu’à l’habitude aujourd’hui, je vous propose, en 3e partie, un blogue consacré au mécanisme d’attention, aux transformers et aux modèles préentraînés. Blogue qui vous permettra de comprendre comment les modèles comme ChatGPT et BERT ont vu le jour.
Gérer le consentement aux témoins
Nous avons à cœur de protéger vos données. Nous utilisons des cookies pour vous offrir une meilleure expérience numérique. En acceptant, vous consentez à notre utilisation de ces cookies.
Fonctionnel
Always active
Le stockage ou l’accès technique est strictement nécessaire dans la finalité d’intérêt légitime de permettre l’utilisation d’un service spécifique explicitement demandé par l’abonné ou l’utilisateur, ou dans le seul but d’effectuer la transmission d’une communication sur un réseau de communications électroniques.
Préférences
Le stockage ou l’accès technique est nécessaire dans la finalité d’intérêt légitime de stocker des préférences qui ne sont pas demandées par l’abonné ou l’utilisateur.
Statistiques
Le stockage ou l’accès technique qui est utilisé exclusivement à des fins statistiques.Le stockage ou l’accès technique qui est utilisé exclusivement dans des finalités statistiques anonymes. En l’absence d’une assignation à comparaître, d’une conformité volontaire de la part de votre fournisseur d’accès à internet ou d’enregistrements supplémentaires provenant d’une tierce partie, les informations stockées ou extraites à cette seule fin ne peuvent généralement pas être utilisées pour vous identifier.
Marketing
Le stockage ou l’accès technique est nécessaire pour créer des profils d’utilisateurs afin d’envoyer des publicités, ou pour suivre l’utilisateur sur un site web ou sur plusieurs sites web ayant des finalités marketing similaires.